
TD3
Published:
TD3
Implementation of TD3 reinforcement learning algorithm
Technical Details
- Framework: PyTorch
- Environment: MuJoCo
- Category: Actor-Critic Methods
This directory contains implementations of the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm for various continuous control environments.
Overview
TD3 is an advanced off-policy actor-critic algorithm designed to address the overestimation bias in DDPG. It introduces three critical improvements:
- Twin Critics: Uses two Q-value networks to reduce overestimation bias through taking the minimum Q-value.
- Delayed Policy Updates: Updates the policy less frequently than the critics to reduce variance.
- Target Policy Smoothing: Adds noise to the target actions to make the algorithm more robust to errors.
Key features of this implementation:
- Actor-Critic architecture with twin critics
- Delayed policy updates
- Target policy smoothing regularization
- Experience replay buffer for stable learning
- Soft target network updates using Polyak averaging
- Exploration using additive noise
- Support for different continuous control environments
Environments
This implementation includes support for the following environments:
- Pendulum-v1: A classic control problem where the goal is to balance a pendulum in an upright position.
- BipedalWalker-v3: A more challenging environment where a 2D biped robot must walk forward without falling.
- HalfCheetah-v5: A MuJoCo environment where a 2D cheetah-like robot must run forward as fast as possible.
Configuration
Each implementation includes a Config class that specifies the hyperparameters for training. You can modify these parameters to experiment with different settings:
exp_name: Name of the experimentseed: Random seed for reproducibilityenv_id: ID of the Gymnasium environmentpolicy_noise: Standard deviation of noise added to target policytotal_timesteps: Total number of training stepslearning_rate: Learning rate for the optimizerbuffer_size: Size of the replay buffergamma: Discount factortau: Soft update coefficient for target networksbatch_size: Batch size for trainingclip: Clipping range for target policy smoothing noiseexploration_fraction: Fraction of total timesteps for explorationlearning_starts: Number of timesteps before learning startstrain_frequency: Frequency of updates to the networks
Architecture
The TD3 implementation includes:
- Actor Network: Determines the best action in a given state
- Twin Critic Networks: Two separate networks that evaluate the Q-value of state-action pairs
- Target Networks: Slowly updated copies of both actor and critics for stability
- Replay Buffer: Stores and samples transitions for training
- Noise Process: Adds exploration noise to actions during training
Improvements Over DDPG
TD3 addresses several shortcomings of DDPG:
- Reducing Overestimation Bias: By using the minimum of two critics, TD3 helps mitigate the overestimation bias that plagues many Q-learning algorithms.
- Stabilized Learning: Delayed policy updates (updating the policy less frequently than the critics) help reduce variance and stabilize learning.
- Smoother Target Values: Adding noise to target actions smooths the value function, making the learning process more robust to errors.
Results
The implementation includes a video recording (TD3_BipedalWalker.mp4) that demonstrates the performance of the trained TD3 agent on the BipedalWalker environment.
Training Visualizations
BipedalWalker Agent
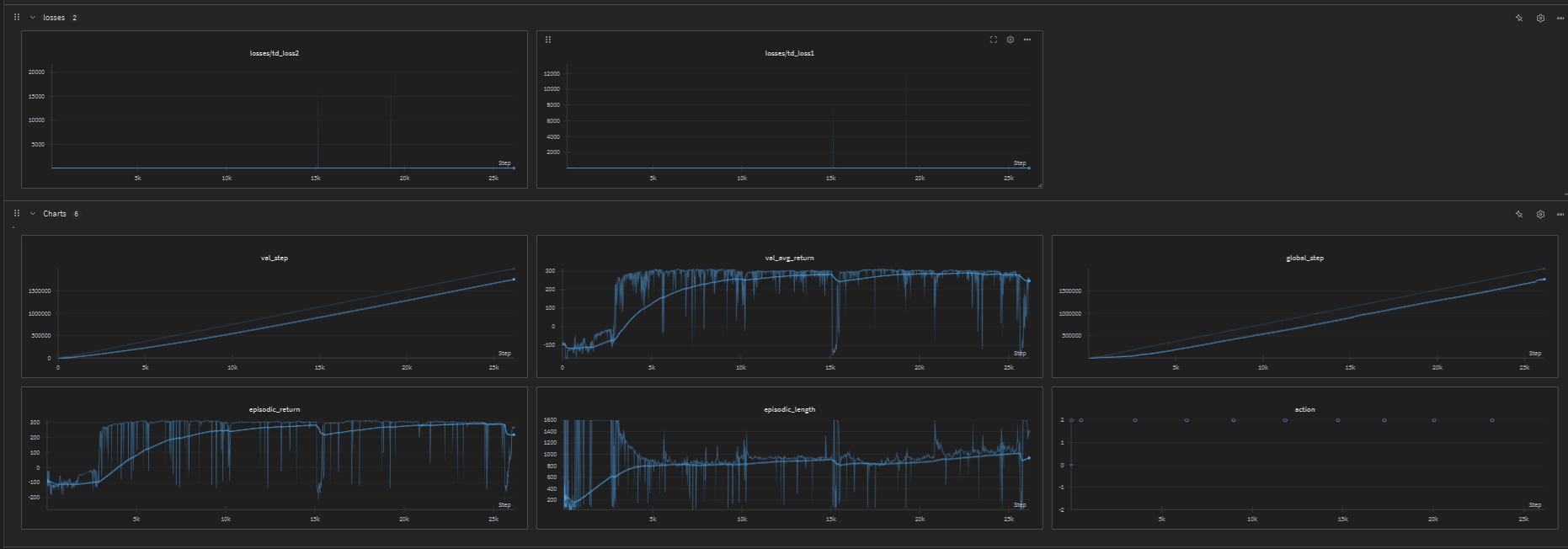
Here’s a GIF showing the trained TD3 agent navigating the BipedalWalker environment:

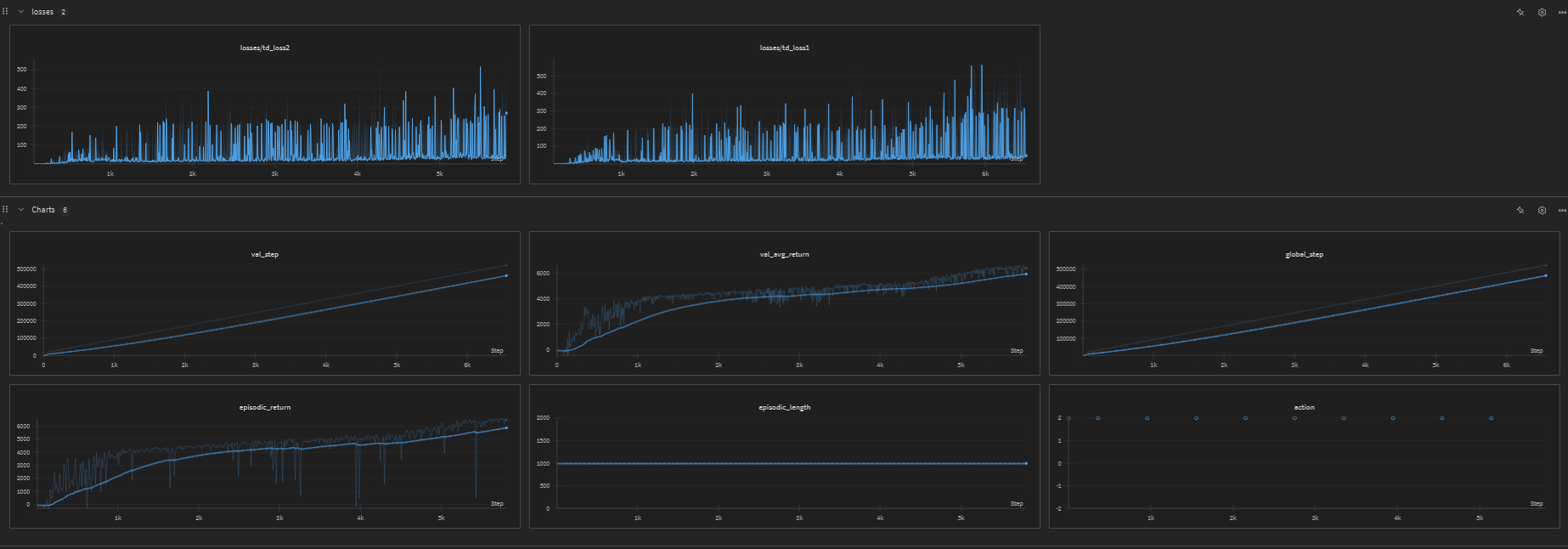
HalfCheetah Training
The following graph shows the training losses for the HalfCheetah environment:
- CleanRL - Inspiration for code structure and implementation style
Source Code
📁 GitHub Repository: TD3 (TD3)
View the complete implementation, training scripts, and documentation on GitHub.