
SAC
Published:
SAC
Implementation of SAC reinforcement learning algorithm
Technical Details
- Framework: PyTorch
- Environment: Gymnasium
- Category: Actor-Critic Methods
This directory contains implementations of the Soft Actor-Critic (SAC) algorithm for various continuous control environments.
Overview
SAC is an off-policy actor-critic algorithm designed for continuous action spaces that optimizes a stochastic policy in an off-policy way. It incorporates several key features:
- Maximum Entropy Reinforcement Learning: Encourages exploration by maximizing the policy entropy along with the expected return.
- Actor-Critic Architecture: Uses a critic to estimate the Q-values and an actor to learn the policy.
- Off-Policy Learning: Can learn from previously collected data, making it sample-efficient.
- Soft Policy Updates: Uses soft updates of the target networks to improve stability.
Key features of this implementation:
- Entropy-regularized reinforcement learning
- Actor-Critic architecture with automatic temperature tuning
- Experience replay buffer for stable learning
- Soft target network updates using Polyak averaging
- Stochastic policy for better exploration
- Support for different continuous control environments
Environments
This implementation includes support for the following environments:
- Pendulum-v1: A classic control problem where the goal is to balance a pendulum in an upright position.
- BipedalWalker-v3: A more challenging environment where a 2D biped robot must walk forward without falling.
Configuration
Each implementation includes a Config class that specifies the hyperparameters for training. You can modify these parameters to experiment with different settings:
exp_name: Name of the experimentseed: Random seed for reproducibilityenv_id: ID of the Gymnasium environmenttotal_timesteps: Total number of training stepslearning_rate: Learning rate for the optimizerbuffer_size: Size of the replay buffergamma: Discount factortau: Soft update coefficient for target networksbatch_size: Batch size for trainingexploration_fraction: Fraction of total timesteps for explorationlearning_starts: Number of timesteps before learning startstrain_frequency: Frequency of updates to the networks
Architecture
The SAC implementation includes:
- Actor Network (Policy): Outputs a mean and log standard deviation for each action dimension, defining a Gaussian distribution over actions.
- Twin Critic Networks: Two separate Q-value networks to mitigate overestimation bias.
- Temperature Parameter (Alpha): Automatically adjusted to maintain a target entropy level.
- Target Networks: Slowly updated copies of the critic networks for stability.
- Replay Buffer: Stores and samples transitions for training.
Key Advantages of SAC
SAC offers several advantages over other continuous control algorithms:
- Sample Efficiency: Off-policy learning allows SAC to reuse past experiences.
- Stability: The entropy term and soft updates help stabilize training.
- Exploration-Exploitation Balance: The maximum entropy framework naturally balances exploration and exploitation.
- Performance: SAC has shown state-of-the-art performance across many continuous control tasks.
- Robustness: Less sensitive to hyperparameter tuning compared to other algorithms.
Logging and Monitoring
Training progress is logged using:
- TensorBoard: Local visualization of training metrics
- Weights & Biases (WandB): Cloud-based experiment tracking (optional)
- Video Capture: Records videos of agent performance at intervals
Results
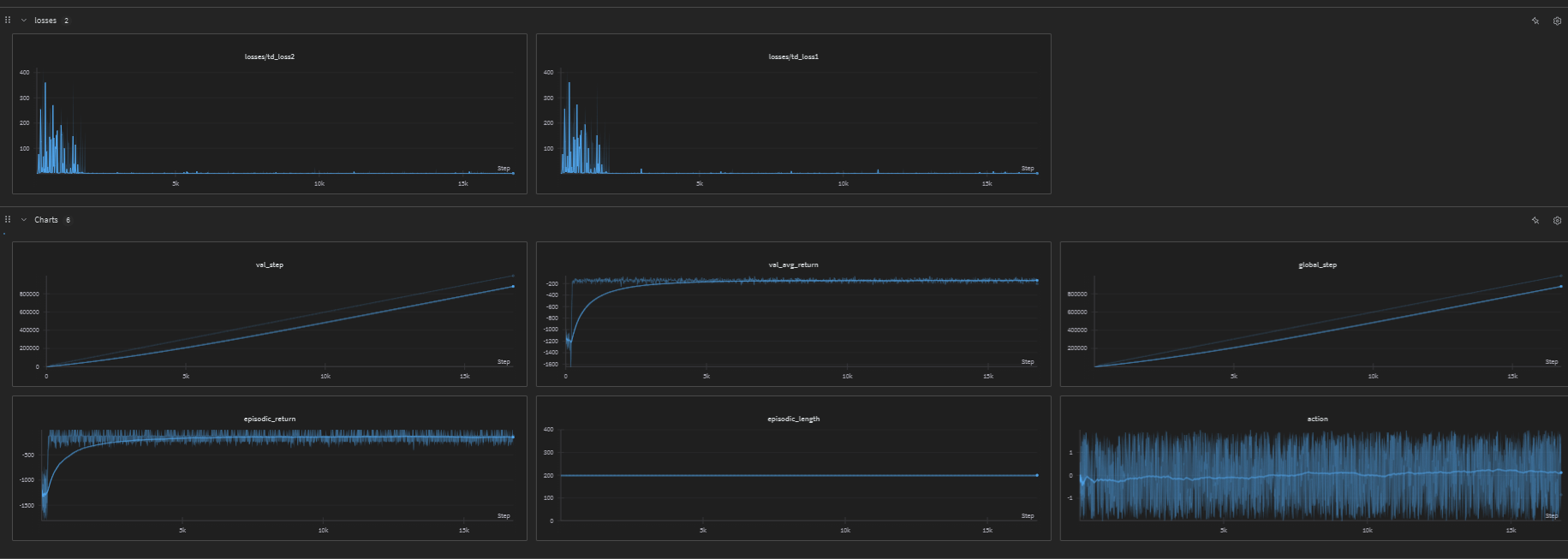
Pendulum
The following image shows the training performance on the Pendulum environment:
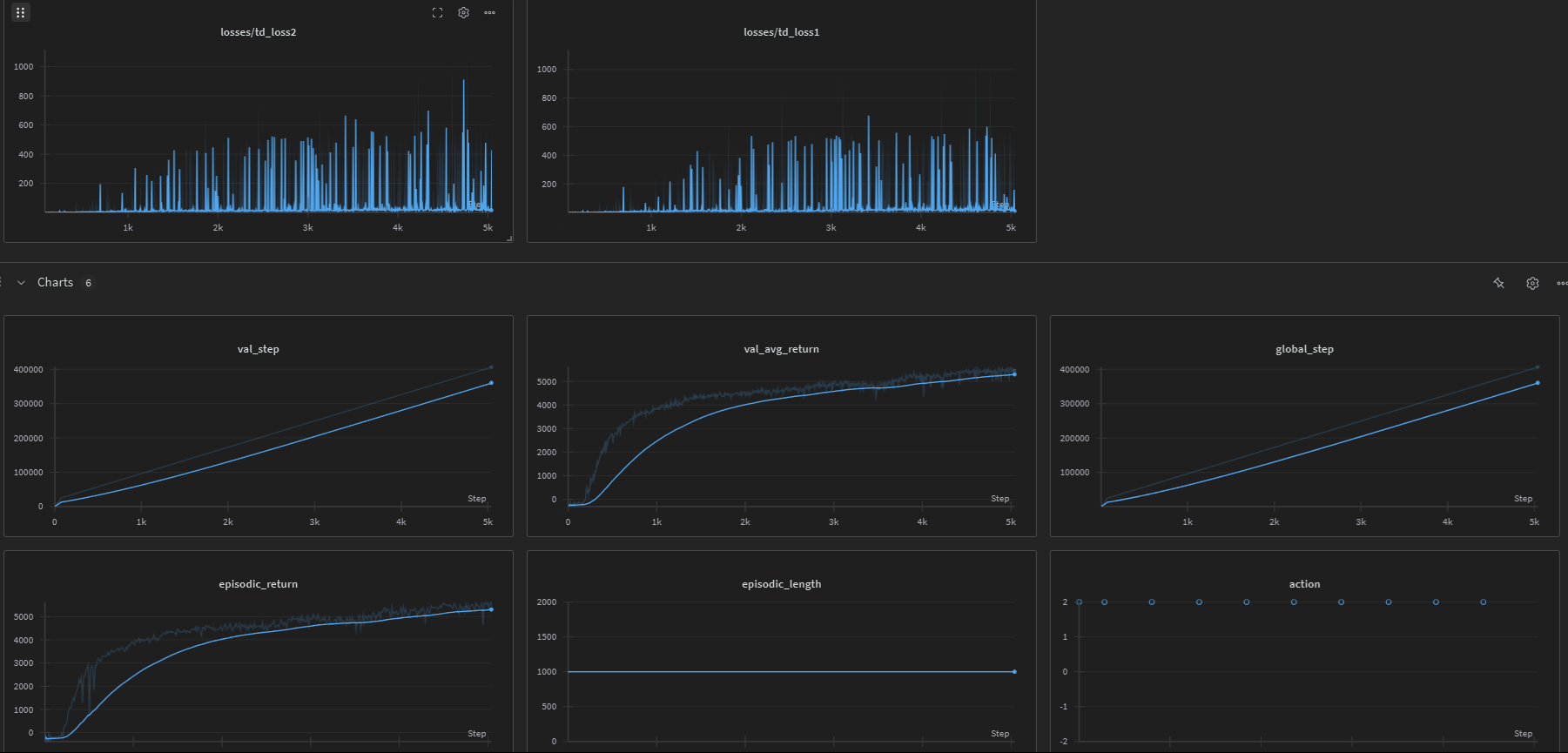
HalfCheetah
Although not explicitly implemented in the current codebase, we have training results for the HalfCheetah environment using SAC:
Source Code
📁 GitHub Repository: SAC (SAC)
View the complete implementation, training scripts, and documentation on GitHub.