
PPO
Published:
PPO
Implementation of PPO reinforcement learning algorithm
Technical Details
- Framework: PyTorch
- Environment: Atari
- Category: Other This directory contains implementations of the Proximal Policy Optimization (PPO) algorithm for various environments in PyTorch.
Overview
PPO is a state-of-the-art policy gradient method that combines the stability of trust region methods with the simplicity and efficiency of first-order optimization. It addresses the issue of choosing the right step size when optimizing policies by introducing a clipped surrogate objective function.
Key features of this implementation:
- Clipped surrogate objective function for stable policy updates
- Actor-Critic architecture with value function for advantage estimation
- Generalized Advantage Estimation (GAE) for reduced variance
- Configurable hyperparameters for different environments
- Two implementations: separate actor-critic networks and unified network
Implementations
This repository includes two main PPO implementations:
- Standard PPO (
train.py): Uses separate networks for the actor (policy) and critic (value function). Applied to the LunarLander environment.
Environments
This implementation has been tested on:
- CartPole-v1: A classic control task where a pole is attached to a cart that moves along a frictionless track.
- LunarLander-v3: A more complex environment where an agent must land a lunar module on a landing pad.
- Pendulum-v1: A continuous control task where the agent learns to balance a pendulum by applying torque.
- BipedalWalker-v3: A continuous control environment where the agent learns to walk forward using bipedal locomotion.
- CarRacing-v3: A continuous control environment where the agent learns to drive a car around a track from a top-down view.
- ViZDoom Basic: A 3D first-person shooter environment where the agent learns to navigate and collect health packs.
For MuJoCo environments (HalfCheetah, Humanoid, Ant, etc.), see the dedicated MuJoCo folder with specialized implementations and detailed documentation.
Configuration
The implementation uses a Config class that specifies hyperparameters for training:
exp_name: Name of the experimentseed: Random seed for reproducibilityenv_id: ID of the Gymnasium environmentepisodes: Number of episodes to trainlr/learning_rate: Learning rate for the optimizergamma: Discount factorclip_value: PPO clipping parameter (epsilon)PPO_EPOCHS: Number of optimization epochs per batchENTROPY_COEFF: Coefficient for entropy bonusmax_steps: Maximum number of steps per episode (fortrain.py)
Additional important parameters:
VALUE_COEFF: Coefficient for the value function loss
Algorithm Details
PPO works by:
- Collecting Experience: The agent interacts with the environment to collect trajectories.
- Computing Advantages: Generalized Advantage Estimation (GAE) is used to estimate the advantage function.
- Policy Update: The policy is updated using the clipped surrogate objective:
L = min(r_t(θ) * A_t, clip(r_t(θ), 1-ε, 1+ε) * A_t)where r_t(θ) is the ratio of new to old policy probabilities, A_t is the advantage, and ε is the clip parameter.
- Value Function Update: The value function is updated to better predict returns.
The clipping mechanism prevents too large policy updates, improving stability without the computational overhead of trust region methods like TRPO.
Architecture
Standard PPO (train.py)
- Actor Network: Maps states to action probabilities
- Critic Network: Estimates the value function
Unified PPO (train_unified.py)
- Shared Layers: Extract features from the state
- Policy Head: Maps features to action probabilities
- Value Head: Maps features to state value estimates
Logging and Monitoring
Training progress is logged using:
- TensorBoard: Local visualization of training metrics
- Weights & Biases (WandB): Cloud-based experiment tracking
- Video Capture: Records videos of agent performance at intervals
Results
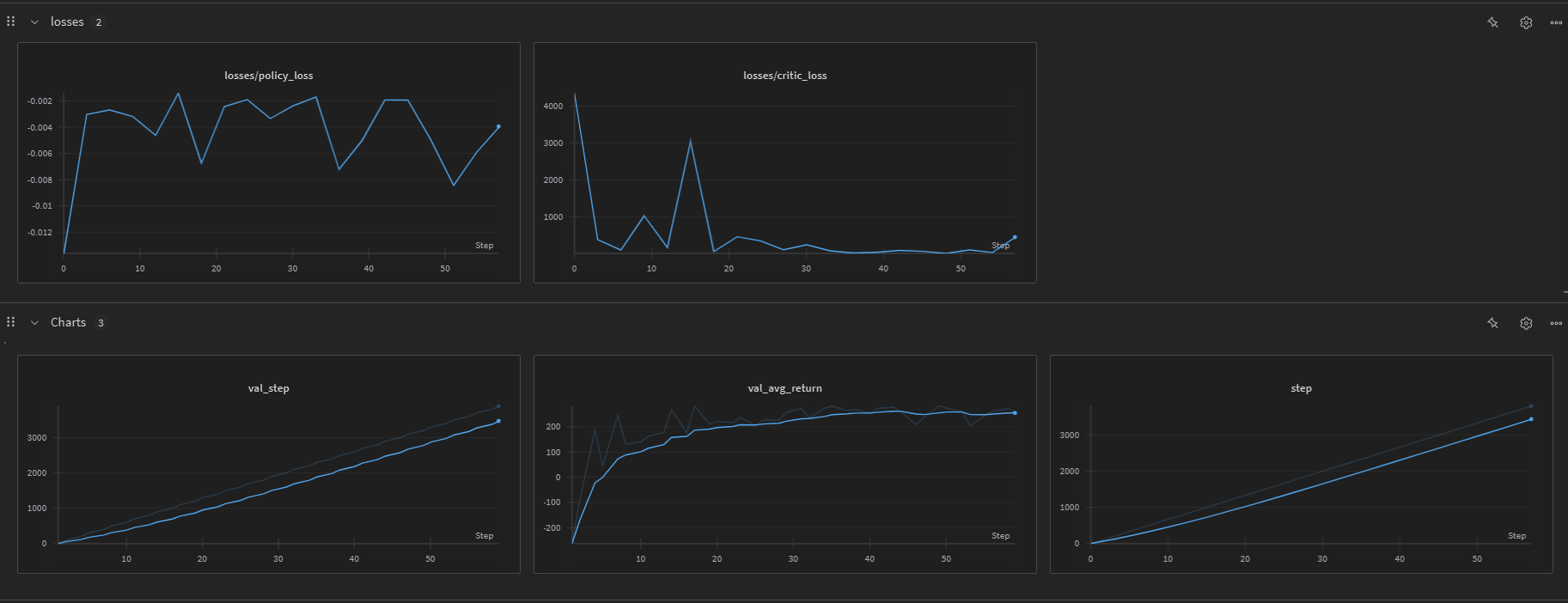
LunarLander
The following image shows the training performance on the LunarLander environment:
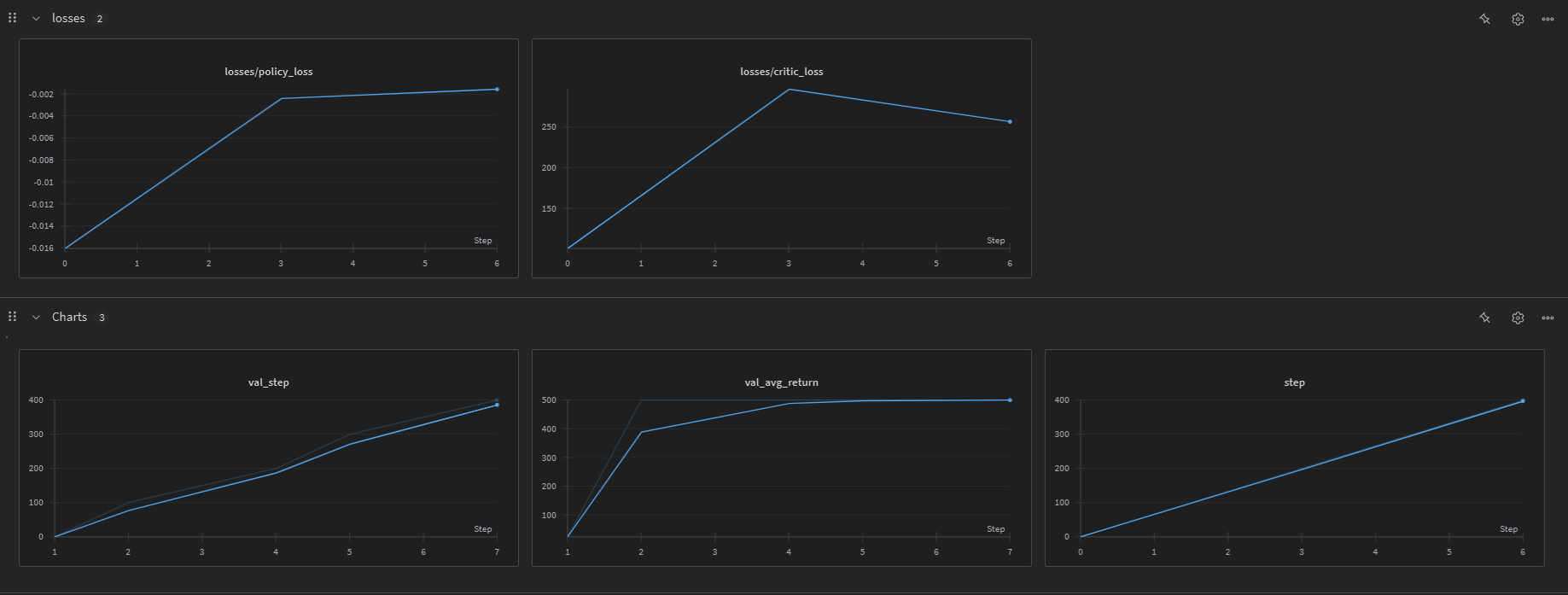
Cartpole
The following image shows the training performance on the CartPole environment:
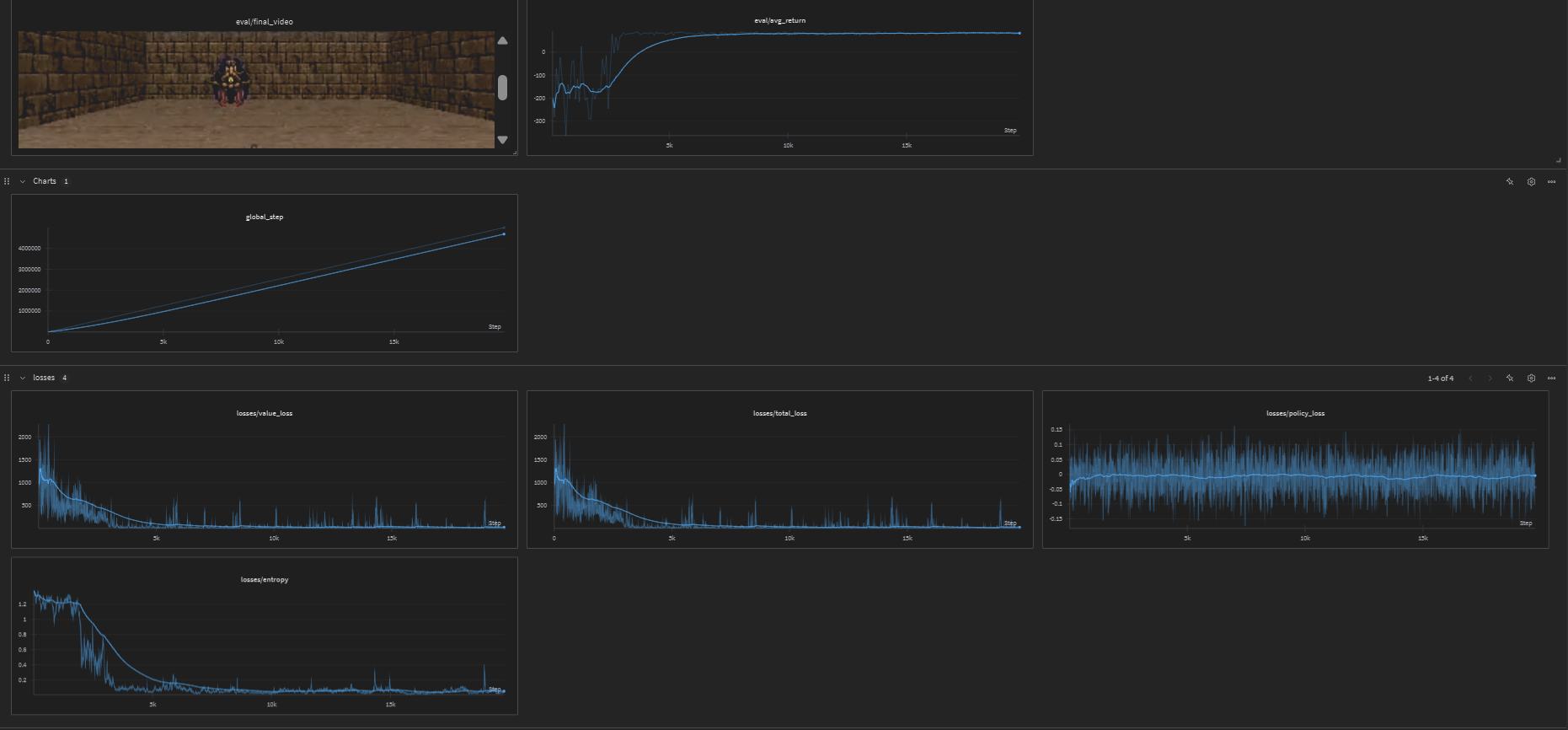
ViZDoom Basic
The following image shows the training performance on the ViZDoom Basic environment:
Agent gameplay demonstration:
ViZDoom Defend the Center
PPO has been successfully applied to the ViZDoom Defend the Center environment, a challenging 3D first-person shooter task where the agent must defend against enemies approaching from all directions.
Agent gameplay demonstration:
Detailed training results and analysis can be found in this comprehensive report: VizDoom Defend The Center PPO - WandB Report
Car Racing
The following image shows the training performance on the CarRacing-v3 environment:
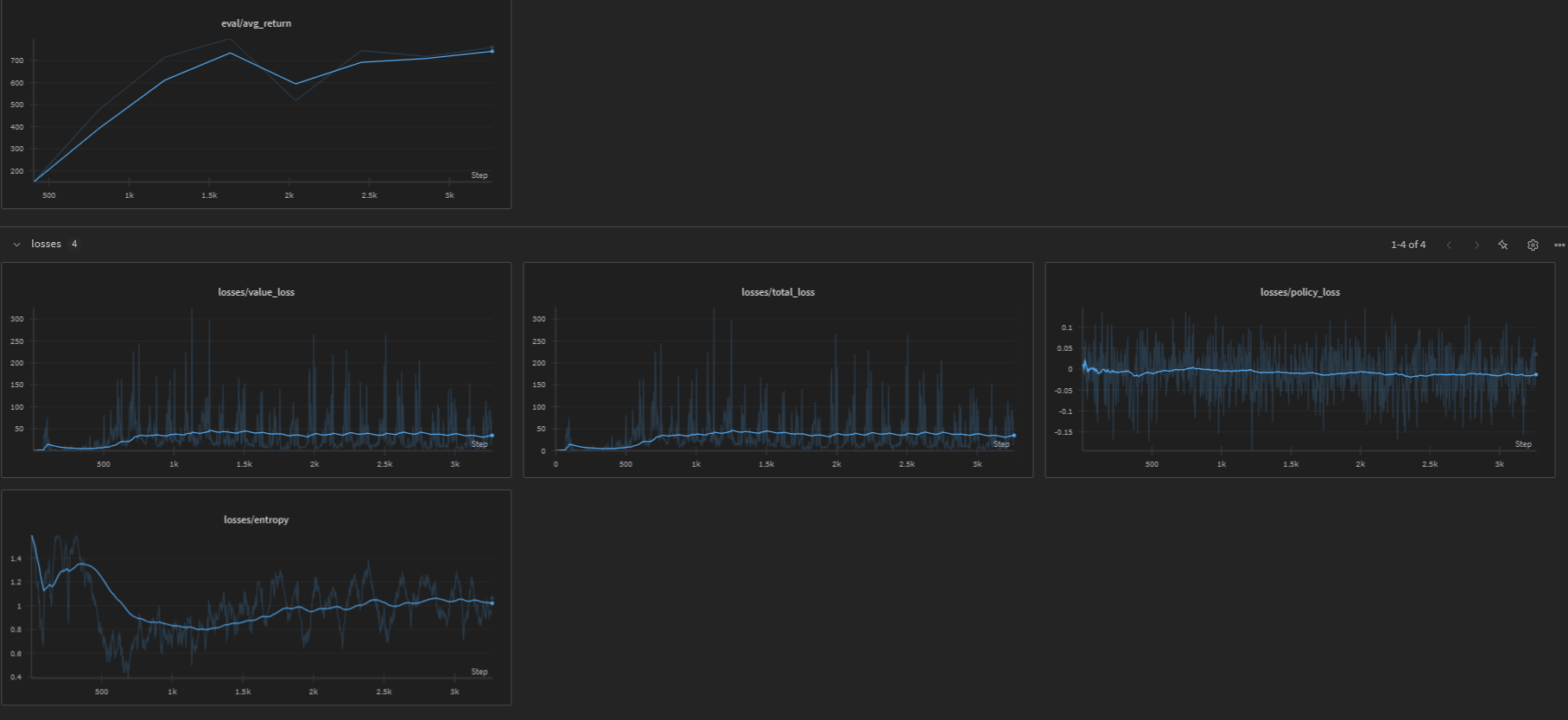

PPO has been successfully applied to the CarRacing-v3 environment, a challenging continuous control task where the agent must learn to drive a car around a randomly generated track. The environment features:
- Continuous action space: Steering, acceleration, and braking
- High-dimensional visual input: 96x96 RGB images from a top-down view
- Complex dynamics: Realistic car physics and track generation
Detailed training results and analysis can be found in this comprehensive report: PPO on Car Racing v3 - WandB Report
Pendulum
PPO has been successfully applied to the Pendulum-v1 environment, a classic continuous control task where the agent must learn to balance a pendulum by applying torque. The environment features:
- Continuous action space: Single continuous action (torque) between -2 and 2
- Continuous state space: 3-dimensional observation (cos(θ), sin(θ), angular velocity)
- Challenging dynamics: The agent must learn to swing up and balance the pendulum at the upright position
The following shows the training performance and agent behavior:

Detailed training results and analysis can be found in this comprehensive report: PPO on Pendulum-v1 - WandB Report
BipedalWalker
PPO has been successfully applied to the BipedalWalker-v3 environment, a challenging continuous control task where the agent must learn to walk forward using bipedal locomotion. The environment features:
- Continuous action space: 4-dimensional continuous actions controlling hip and knee torques for both legs
- Continuous state space: 24-dimensional observation including hull angle, angular velocity, leg positions, and velocities
- Challenging dynamics: The agent must learn to coordinate multiple joints to achieve stable walking while maintaining balance
The following shows the training performance and agent behavior:

Detailed training results and analysis can be found in this comprehensive report: PPO on BipedalWalker-v3 - WandB Report
Dependencies
- PyTorch
- Gymnasium
- NumPy
- WandB (optional, for experiment tracking)
- TensorBoard
- OpenCV
- Tqdm
References
- CleanRL - Inspiration for code structure and implementation style
Source Code
📁 GitHub Repository: PPO (PPO)
View the complete implementation, training scripts, and documentation on GitHub.