
DQN
Published:
DQN
Implementation of DQN reinforcement learning algorithm
Technical Details
- Framework: PyTorch
- Environment: Gymnasium
- Category: Other This repository contains an implementation of Deep Q-Network (DQN) for solving the CartPole-v1 environment from OpenAI Gym (Gymnasium). The implementation includes features such as experience replay, target networks, and epsilon-greedy exploration.
Overview
The main training script (train.py) implements a DQN agent to solve the CartPole-v1 environment, where the goal is to balance a pole on a moving cart. The agent learns to take actions (move left or right) to keep the pole upright for as long as possible.
Features
- Deep Q-Network (DQN): Uses a neural network to approximate the Q-function
- Experience Replay: Stores transitions in a replay buffer to break correlations between consecutive samples
- Target Network: Uses a separate target network to stabilize learning
- Epsilon-Greedy Exploration: Balances exploration and exploitation with a decaying epsilon
- Evaluation: Periodically evaluates the model and saves videos of the agent’s performance
- Logging: Includes logging to TensorBoard and Weights & Biases (wandb) for experiment tracking
- Video Recording: Records videos during training and evaluation for visualization
Requirements
gymnasium
torch
numpy
tqdm
stable-baselines3
wandb
imageio
opencv-python
tensorboard
huggingface_hub
Configuration
The project is configured through the Config class, which includes the following parameters:
- Environment Settings:
env_id: The Gym environment ID (default: “CartPole-v1”)seed: Random seed for reproducibility (default: 42)
- Training Parameters:
total_timesteps: Total number of timesteps to train (default: 20,000)learning_rate: Learning rate for the optimizer (default: 2.5e-4)buffer_size: Size of the replay buffer (default: 10,000)gamma: Discount factor (default: 0.99)tau: Soft update parameter for target network (default: 1.0)target_network_frequency: Frequency of target network updates (default: 50)batch_size: Batch size for training (default: 128)start_e: Initial exploration rate (default: 1.0)end_e: Final exploration rate (default: 0.05)exploration_fraction: Fraction of total timesteps over which to decay epsilon (default: 0.5)learning_starts: Number of timesteps before starting to learn (default: 1,000)train_frequency: Frequency of training steps (default: 10)
- Logging & Saving:
capture_video: Whether to capture videos (default: True)save_model: Whether to save model checkpoints (default: True)upload_model: Whether to upload model to Hugging Face Hub (default: True)hf_entity: Hugging Face username (default: “”)use_wandb: Whether to use Weights & Biases for logging (default: True)wandb_project: WandB project name (default: “cleanRL”)wandb_entity: WandB username/team (default: “”)
Usage
To run the training script:
python train.py
Model Architecture
The Q-network (QNet) is a simple fully-connected neural network with the following architecture:
- Input layer: State space dimension
- Hidden layer 1: 256 units with ReLU activation
- Hidden layer 2: 512 units with ReLU activation
- Output layer: Action space dimension (2 for CartPole-v1)
Evaluation
The agent is evaluated periodically during training (every 1,000 timesteps by default). Evaluation metrics include:
- Average return over multiple episodes
- Videos of the agent’s performance
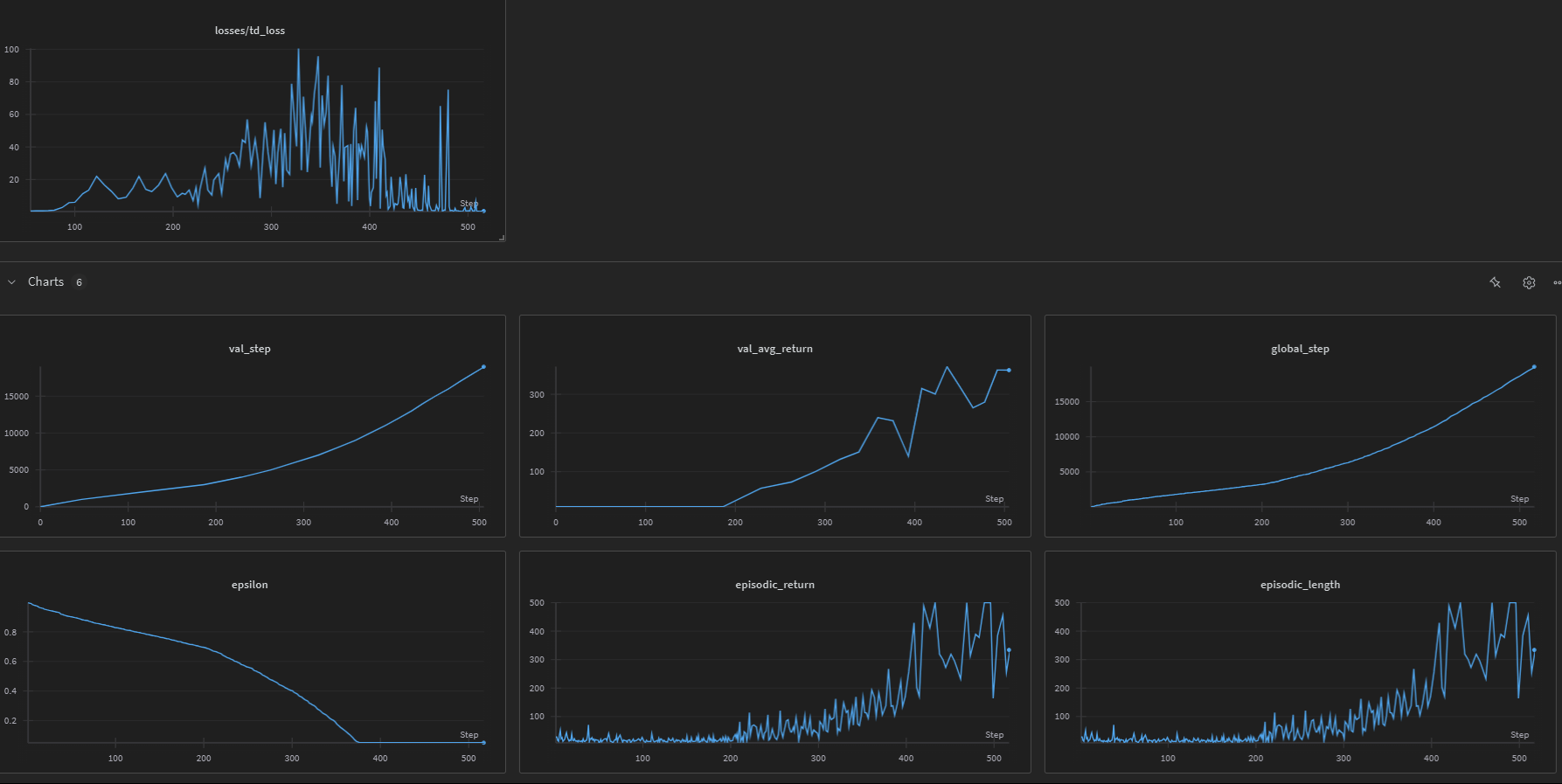
Training Progress
Agent Performance
Here’s a video showing the trained agent in action:
Click to see video (GIF format)
 -->Logging
Training metrics are logged to both TensorBoard and Weights & Biases (if enabled), including:
- Episodic returns
- Episodic lengths
- TD loss
- Q-values
- Exploration rate (epsilon)
Results
After successful training, the agent should be able to balance the pole for the maximum episode length (500 timesteps in CartPole-v1).
References
- Deep Q-Network (DQN) Paper
- CleanRL - This implementation is inspired by the CleanRL project
License
This project is licensed under the MIT License - see the LICENSE file for details.
Source Code
📁 GitHub Repository: DQN (DQN)
View the complete implementation, training scripts, and documentation on GitHub.