
DQN Atari
Published:
DQN Atari
Implementation of DQN-atari reinforcement learning algorithm
Technical Details
- Framework: PyTorch
- Environment: Atari
- Category: Other This repository contains an implementation of Deep Q-Network (DQN) for solving the BreakoutNoFrameskip-v4 environment from Atari. The implementation includes features such as experience replay, target networks, epsilon-greedy exploration, and convolutional neural networks for processing visual input.

Overview
The main training script (train.py) implements a DQN agent to solve the BreakoutNoFrameskip-v4 environment, where the goal is to control a paddle to bounce a ball and break bricks. The agent learns to take actions (move left, right, or stay still) to maximize the score by breaking as many bricks as possible while keeping the ball in play.
Features
- Deep Q-Network (DQN): Uses a convolutional neural network to approximate the Q-function from raw pixel input
- Atari Preprocessing: Includes frame skipping, grayscale conversion, frame stacking, and image resizing
- Experience Replay: Stores transitions in a replay buffer to break correlations between consecutive samples
- Target Network: Uses a separate target network to stabilize learning
- Epsilon-Greedy Exploration: Balances exploration and exploitation with a decaying epsilon
- Evaluation: Periodically evaluates the model and saves videos of the agent’s performance
- Logging: Includes logging to TensorBoard for experiment tracking
- Video Recording: Records videos during training and evaluation for visualization
Requirements
gymnasium
torch
numpy
tqdm
stable-baselines3
imageio
opencv-python
tensorboard
huggingface_hub
ale-py
Configuration
The project is configured through the Config class, which includes the following parameters:
- Environment Settings:
env_id: The Atari environment ID (default: “BreakoutNoFrameskip-v4”)seed: Random seed for reproducibility (default: 42)
- Training Parameters:
total_timesteps: Total number of timesteps to train (default: 1,000,000)learning_rate: Learning rate for the optimizer (default: 2.5e-4)buffer_size: Size of the replay buffer (default: 20,000)gamma: Discount factor (default: 0.99)tau: Soft update parameter for target network (default: 1.0)target_network_frequency: Frequency of target network updates (default: 50)batch_size: Batch size for training (default: 256)start_e: Initial exploration rate (default: 1.0)end_e: Final exploration rate (default: 0.05)exploration_fraction: Fraction of total timesteps over which to decay epsilon (default: 0.3)learning_starts: Number of timesteps before starting to learn (default: 1,000)train_frequency: Frequency of training steps (default: 4)
- Logging & Saving:
capture_video: Whether to capture videos (default: True)save_model: Whether to save model checkpoints (default: True)upload_model: Whether to upload model to Hugging Face Hub (default: True)hf_entity: Hugging Face username (default: “”)
Model Architecture
The Q-network (QNet) is a convolutional neural network designed for processing Atari frames with the following architecture:
- Conv Layer 1: 32 filters, 8x8 kernel, stride 4, ReLU activation
- Conv Layer 2: 32 filters, 4x4 kernel, stride 2, ReLU activation
- Conv Layer 3: 64 filters, 3x3 kernel, stride 3, ReLU activation
- Fully Connected 1: 512 units with ReLU activation
- Fully Connected 2: 512 units with ReLU activation
- Output layer: Action space dimension (4 for Breakout: NOOP, FIRE, RIGHT, LEFT)
Usage
To run the training script:
python train.py
Atari Preprocessing
The Breakout environment uses several preprocessing steps to make the raw pixel input suitable for the DQN:
- Frame skipping: Every action is repeated for 4 frames to speed up training
- Grayscale conversion: RGB frames are converted to grayscale
- Frame resizing: Images are resized to 84x84 pixels
- Frame stacking: 4 consecutive frames are stacked to provide temporal information
- Pixel normalization: Pixel values are scaled to [0, 1] range
Evaluation
The agent is evaluated periodically during training. Evaluation metrics include:
- Average return over multiple episodes
- Videos of the agent’s performance
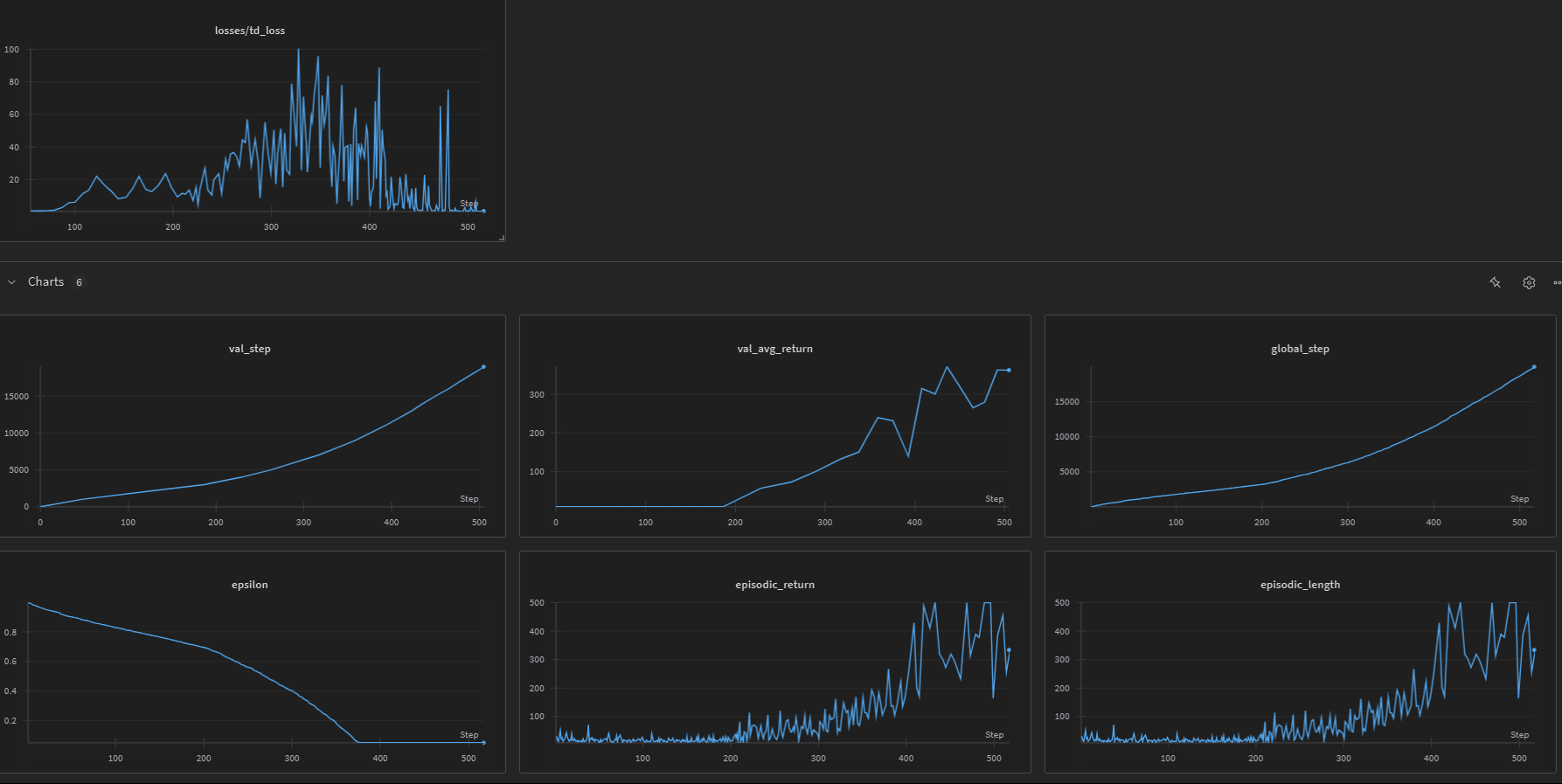
Training Progress
Agent Performance
Here’s a video showing the trained agent in action:
Click to see video (GIF format)
Logging
Training metrics are logged to TensorBoard, including:
- Episodic returns
- Episodic lengths
- TD loss
- Q-values
- Exploration rate (epsilon)
Results
After successful training, the agent should be able to achieve high scores in Breakout by learning to effectively control the paddle to break bricks and keep the ball in play. The game terminates when all bricks are destroyed or all lives are lost.
References
- Deep Q-Network (DQN) Paper
- CleanRL - This implementation is inspired by the CleanRL project
License
This project is licensed under the MIT License - see the LICENSE file for details.
Source Code
📁 GitHub Repository: DQN Atari (DQN Atari)
View the complete implementation, training scripts, and documentation on GitHub.