
A2C (A2C)
Published:
A2C (A2C)
Implementation of A2C reinforcement learning algorithm
Technical Details
- Framework: PyTorch
- Environment: LunarLander
- Category: Actor-Critic Methods
Overview
This repository contains an implementation of the Advantage Actor-Critic (A2C) algorithm, a policy gradient method that combines the benefits of both policy-based and value-based reinforcement learning. The implementation is built with PyTorch and supports training on various Gymnasium environments, with a focus on the CartPole-v1 environment.
Results
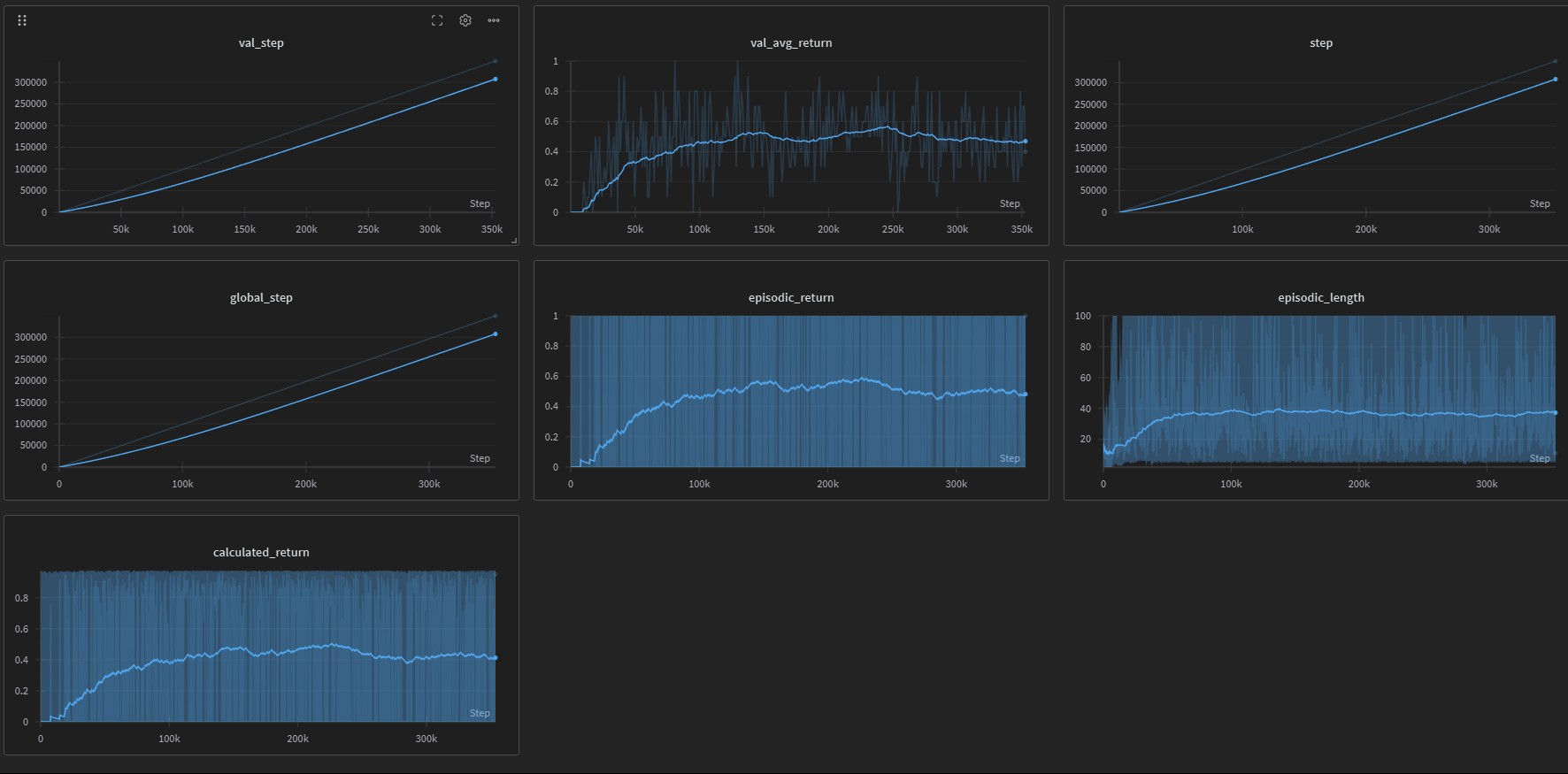
Frozen Lake Environment
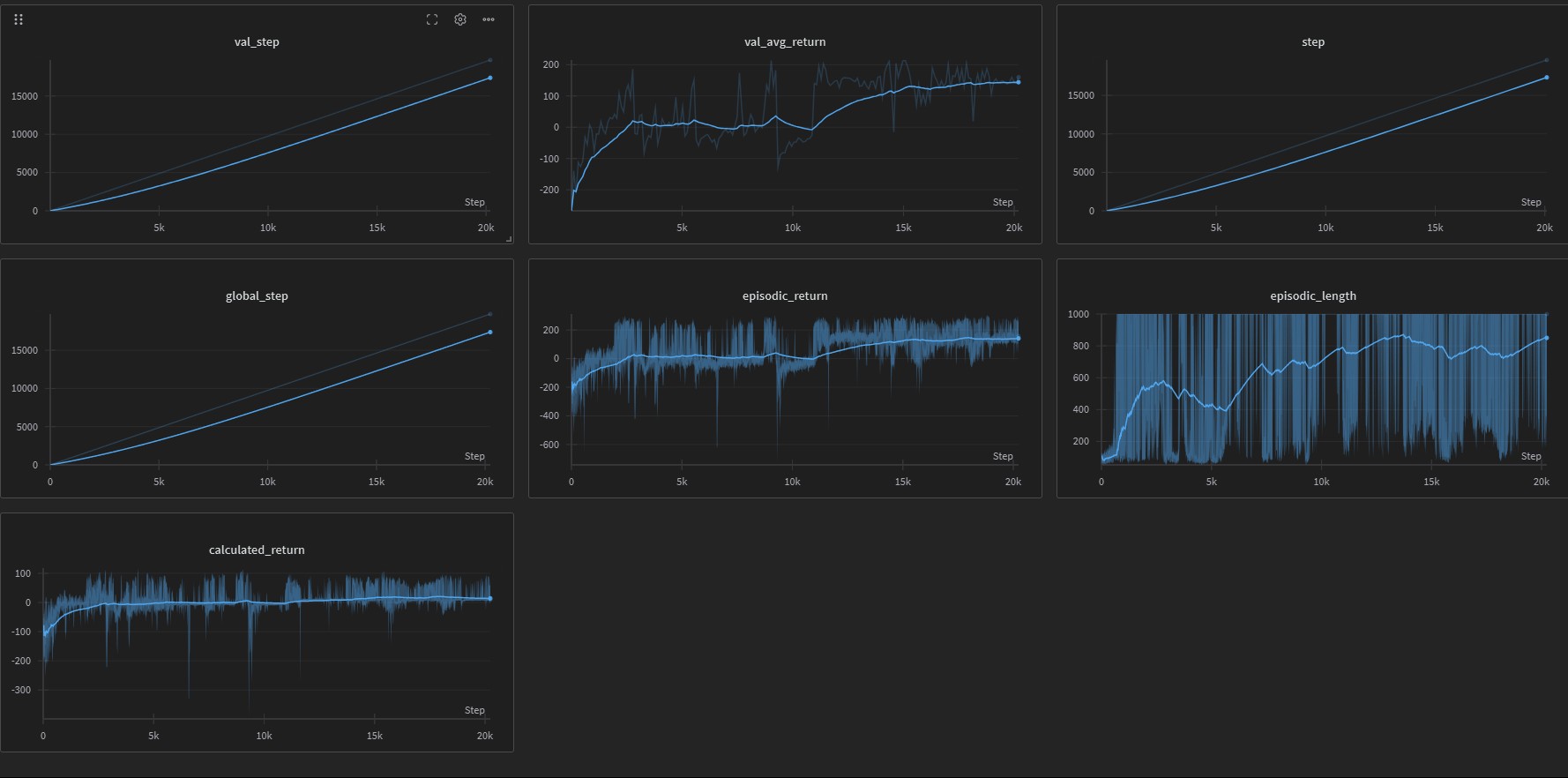
Lunar Lander Environment
Algorithm Description
A2C is a synchronous, deterministic variant of the Asynchronous Advantage Actor-Critic (A3C) algorithm. It uses two neural networks:
- Actor Network: Learns a policy that maps states to actions
- Critic Network: Estimates the value function to evaluate the quality of states
The key advantage of A2C over vanilla policy gradient methods (like REINFORCE) is the use of the advantage function, which reduces variance during training by subtracting a baseline (the value function) from the returns.
The Algorithm Steps
- Initialize actor and critic networks
- For each episode:
- Collect trajectory by following the current policy
- For each step in the trajectory:
- Calculate discounted returns
- Estimate state values using the critic network
- Calculate advantages (returns - values)
- Update the actor network using advantage-weighted policy gradients
- Update the critic network to better predict state values
- Repeat until convergence
Implementation Details
Network Architecture
Actor Network:
- Input layer matching state space dimensions
- Two hidden layers (32 nodes each) with ReLU activation
- One hidden layer (16 nodes) with ReLU activation
- Output layer matching action space dimensions with softmax activation
Critic Network:
- Input layer matching state space dimensions
- One hidden layer (32 nodes) with ReLU activation
- One hidden layer (16 nodes) with ReLU activation
- Output layer with a single value prediction
Key Features
- Separate Actor-Critic Architecture: Maintains distinct networks for policy and value estimation
- Advantage Calculation: Uses the difference between returns and value estimates to reduce variance
- Policy Updates: Uses the advantages to weight policy gradients
- Value Function Learning: Uses MSE loss to train the critic network
- Gradient and Parameter Monitoring: Tracks training dynamics with WandB
- Evaluation: Periodically evaluates policy performance
- Video Recording: Captures agent behavior for visualization
Usage
Prerequisites
- Python 3.8+
- PyTorch
- Gymnasium
- Weights & Biases (for logging)
- TensorBoard
- tqdm, numpy, imageio, cv2
Configuration
The Config class contains all hyperparameters and settings:
class Config:
# Experiment settings
exp_name = "A2C-CartPole"
seed = 42
env_id = "CartPole-v1"
episodes = 2000
# Training parameters
learning_rate = 2e-3
gamma = 0.99 # Discount factor
# Logging & saving
capture_video = True
save_model = True
use_wandb = True
wandb_project = "cleanRL"
Running the Training
python train.py
Monitoring
The implementation integrates with Weights & Biases for comprehensive monitoring:
- Episode Returns: Tracks performance over time
- Actor and Critic Losses: Monitors learning progress
- Advantage Values: Shows the effectiveness of the advantage function
- Gradient Statistics: Helps identify training instability
- Parameter Statistics: Tracks weight distribution changes
- Evaluation Videos: Records agent behavior periodically
Results
A2C typically achieves better sample efficiency and stability compared to vanilla policy gradient methods like REINFORCE. The implementation includes:
- Tensorboard logging for local visualization
- WandB integration for comprehensive tracking
- Video recording of trained agents
Advantages of A2C over REINFORCE
- Reduced Variance: The advantage function reduces the variance of policy gradient estimates
- Better Sample Efficiency: Generally learns faster with fewer samples
- Stability: More stable training due to the critic network’s baseline
- State-Value Estimation: Provides value function approximation as an additional output
Extending the Implementation
To adapt this implementation to other environments:
- Change the
env_idin the Config class - Adjust the actor and critic network architectures based on state/action dimensions
- Tune hyperparameters like learning rate and discount factor
- Consider adding features like entropy regularization or n-step returns
Theoretical Background
The A2C algorithm uses the policy gradient theorem with an advantage function:
| ∇θ J(θ) = E[∇θ log π(a | s;θ) A(s,a)] |
Where:
- J(θ) is the expected return
-
π(a s;θ) is the policy - A(s,a) is the advantage function, defined as: A(s,a) = Q(s,a) - V(s) ≈ r + γV(s’) - V(s)
References
- Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., … & Kavukcuoglu, K. (2016). Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning.
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
License
This project is open source and available under the MIT License.
Source Code
📁 GitHub Repository: A2C (A2C)
View the complete implementation, training scripts, and documentation on GitHub.