
VAE
VAE
Overview
From scratch implementation of VAE
Technical Details
- Framework: PyTorch
- Dataset: MNIST
- Category: Computer Vision
Implementation Details
I implemented a Variational Autoencoder Architecture from Scratch using PyTorch on the CelebA dataset for high-resolution face generation and reconstruction.
Auto-Encoding Variational Bayes
Results
Original vs Reconstructed Images
The following images show the comparison between original CelebA face images (top row) and their reconstructions by the VAE (bottom row):
🖼️ View Results > Note: If images don’t load, please check the data/ folder in this repository:
{kind=link}
data/image.png- Reconstruction comparison resultsdata/losses.jpg- Training loss curvesdata/arithmetic.jpg- Latent space visualizationsdata/samples.jpg- Generated sample faces from latent space
VAE: Original (top) vs Reconstructed (bottom) - Shows the model’s ability to reconstruct high-resolution face images from the latent space representation.
Training Progress
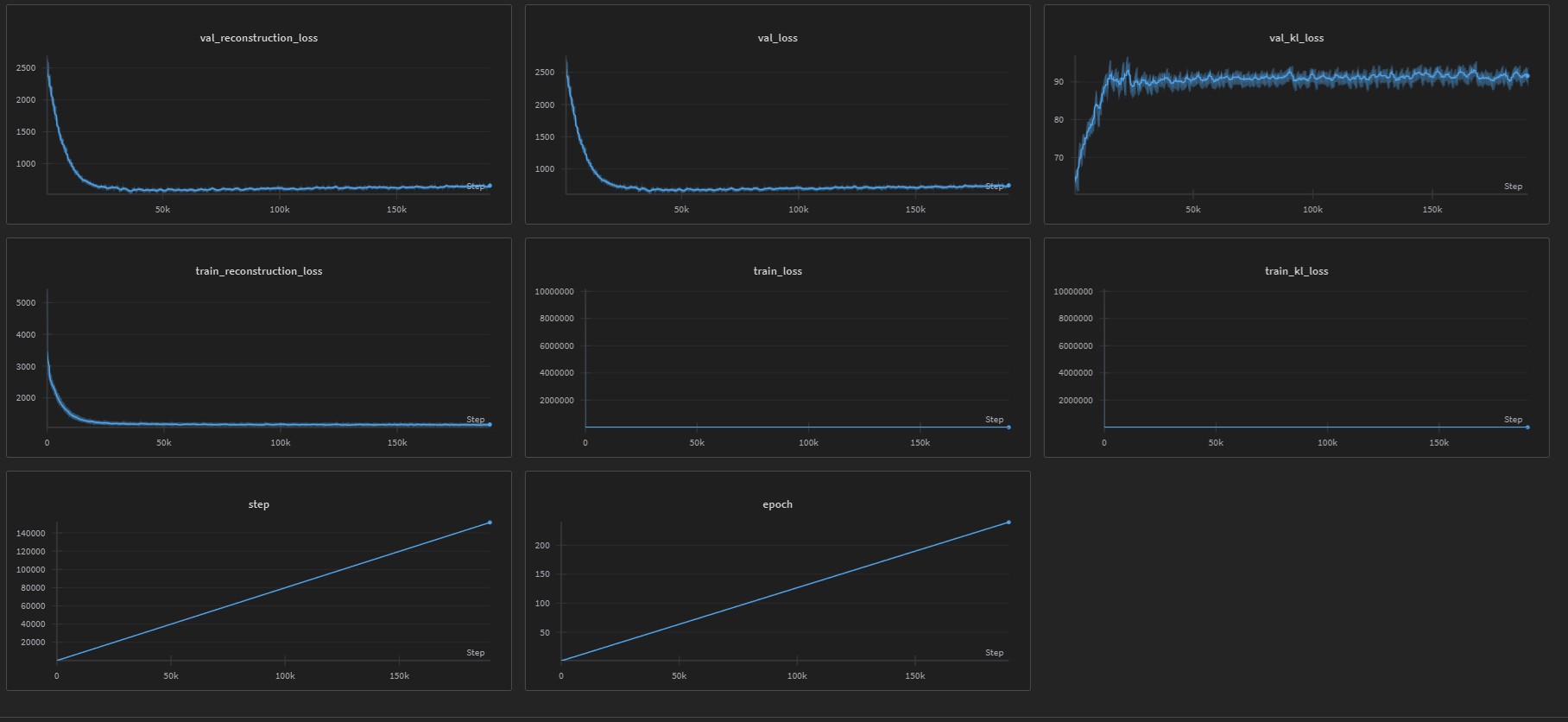{kind=link}
Training and validation losses over epochs showing convergence of reconstruction and KL divergence losses.
Latent Space Arithmetic
🔗 View 🔢 View Latent Arithmetic
{kind=link}
Latent space interpolation and arithmetic operations demonstrating the smooth and meaningful latent representations learned by the VAE.
Generated Samples
{kind=link}
Random samples generated from the latent space showing the diversity and quality of faces that the VAE can produce.
Model Hyperparameters
| Parameter | Value | Description |
|---|---|---|
input_dim |
3 | Input channels (RGB color images). |
hidden_dim |
128 | Hidden dimension for convolutional layers. |
output_dim |
32 | Latent space dimension (bottleneck). |
batch_size |
32 | The number of samples processed before the model is updated. |
learning_rate |
0.0005 | Learning rate for Adam optimizer. |
epochs |
200 | Number of training epochs. |
leaky_relu |
0.01 | Negative slope for LeakyReLU activation. |
image_size |
128x128 | Input image resolution for CelebA faces. |
Dataset
CelebA: Large-scale CelebFaces Attributes Dataset
- 202,599 face images of celebrities
- High-resolution RGB images (128x128 for this implementation)
- Rich variety of facial expressions, poses, and lighting conditions
- Dataset split: 80% training, 20% validation
Data Preprocessing:
- Resize to 128x128 pixels
- Convert to RGB tensors
- Normalize to [0, 1] range
- No additional data augmentation to preserve face structure
Frameworks:
Pytorch
Architecture
Encoder:
- 4 Convolutional layers with LeakyReLU activation
- Progressive channel increase: 3 → 128 → 256 → 256 → 256
- Stride 2 for downsampling to reduce spatial dimensions
- Flatten and linear layers for mean and log variance (reparameterization trick)
- Output: 32-dimensional latent space
Decoder:
- Linear layer to expand 32D latent representation to 262,144 dimensions
- Reshape to 256 × 32 × 32 feature maps
- 4 Transposed Convolutional layers with LeakyReLU activation
- Progressive channel decrease: 256 → 256 → 256 → 128 → 3
- Stride 2 for upsampling to reconstruct 128×128 images
- Sigmoid activation for final RGB output [0, 1]
Training Details
Optimizer: Adam with learning rate 0.0005
Loss Function: Reconstruction Loss (MSE) + KL Divergence
Training/Validation Split: 80/20
Device: CUDA (with automatic CPU fallback)
Progress Tracking: tqdm progress bars with real-time loss monitoring
Logging: Weights & Biases (wandb) for experiment tracking
VAE-Specific Components
Reparameterization Trick: Enables backpropagation through stochastic sampling
KL Divergence: Regularizes latent space to follow standard normal distribution
Latent Space: 32-dimensional for rich face feature representation
Loss Weighting: Balanced reconstruction and KL terms for stable training
Final Training Metrics:
- Reconstruction Loss: MSE between original and reconstructed images
- KL Loss: Ensures latent variables follow standard normal distribution
- Total Loss: Weighted combination optimizing both reconstruction quality and latent space structure
Files in Repository
Notebooks
celeba-variational-autoencoders.ipynb- Main implementation with CelebA datasetvariational-autoencoders.ipynb- Original MNIST implementationmodel.ipynb- Model architecture experimentsinference_vae.py- Inference script for generating new faces
Data
data/image.png- Sample reconstruction results visualizationdata/losses.jpg- Training loss curves and convergence plotsdata/arithmetic.jpg- Latent space interpolation and arithmetic examplesdata/samples.jpg- Generated sample faces from latent space
Image Loading Issues? If images don’t display in your markdown viewer:
- Navigate to the
data/folder directly to view images- Try using absolute paths:
./data/image.png- Some markdown viewers require the repository to be cloned locally
- GitHub should display the images correctly in the web interface
Model Checkpoints
vae_checkpoint_epoch_240.pth- Trained model weights after 240 epochs
Usage
Training the Model
- Setup Environment:
pip install torch torchvision tqdm wandb torchinfo matplotlib - Prepare CelebA Dataset:
- Download CelebA dataset
- Place images in
/kaggle/input/celeba-dataset/img_align_celeba/img_align_celeba/ - Or modify the
image_dirpath in the notebook
- Run Training:
- Open
celeba-variational-autoencoders.ipynb - Execute cells sequentially
- Monitor progress with tqdm progress bars
- Track metrics on Weights & Biases
- Open
Inference
Use the trained model for:
- Image Reconstruction: Encode and decode existing faces
- Face Generation: Sample from latent space to generate new faces
- Latent Interpolation: Smooth transitions between faces
# Load trained model
checkpoint = torch.load('vae_checkpoint_epoch_240.pth')
model.load_state_dict(checkpoint['model_state_dict'])
# Generate new faces
with torch.no_grad():
z = torch.randn(16, 32).to(device) # Sample from latent space
generated_faces = model.decoder(z)
Frameworks:
PyTorch
Source Code
📁 GitHub Repository: VAE
View the complete implementation, training scripts, and documentation on GitHub.