
TTS
TTS
Overview
From scratch implementation of TTS
Technical Details
- Framework: PyTorch
- Dataset: Gigaspeech
- Category: Audio/Speech
Implementation Details
Trained a small transformer based TTS model coded and trained from scratch in Pytorch
(will be uploading the implementation of Wavenet soon)
Neural Speech Synthesis with Transformer Network
Model Hyperparameters
Core Architecture
| Parameter | Value | Description |
|---|---|---|
batch_size |
32 | Number of samples per batch |
max_lr |
6e-4 | Maximum learning rate |
dropout |
0.1 | General dropout rate |
epochs |
10 | Total training epochs |
block_size |
80 | Sequence length in tokens |
src_vocab_size |
dynamic | Source vocabulary size |
phenome_embeddings_dims |
512 | Phoneme embedding dimension |
embeddings_dims |
512 | Main embedding dimension |
prenet_encoder_embeddings_dims |
512 | Encoder prenet dimension |
embeddings_dims_decoder |
256 | Decoder-specific embedding dimension |
attn_dropout |
0.1 | Attention dropout rate |
no_of_heads |
4 | Attention heads per layer |
no_of_decoder_layers |
8 | Number of decoder layers |
weight_decay_optim |
0.01 | Optimizer weight decay |
hidden_dim |
2048 (4×512) | FFN hidden dimension |
clip |
1.0 | Gradient clipping threshold |
Audio Processing
| Parameter | Value | Description |
|————————-|———-|———————————————-|
| log_mel_features | 80 | Mel spectrogram channels |
| kernel_size | 5 | Convolution kernel size |
| stride | (2,10) | Convolution stride (time, freq) |
| sr, SAMPLING_RATE | 16000 | Audio sample rate (Hz) |
| N_MELS | 80 | Number of Mel bands |
| WINDOW_DURATION | 0.050s | Analysis window duration |
| STRIDE_DURATION | 0.0125s | Window stride duration |
| max_t | 512 | Maximum spectrogram time steps |
| n_channels | 80 | Input spectrogram channels |
Dataset
Gigaspeech (can be used)
Frameworks:
Pytorch
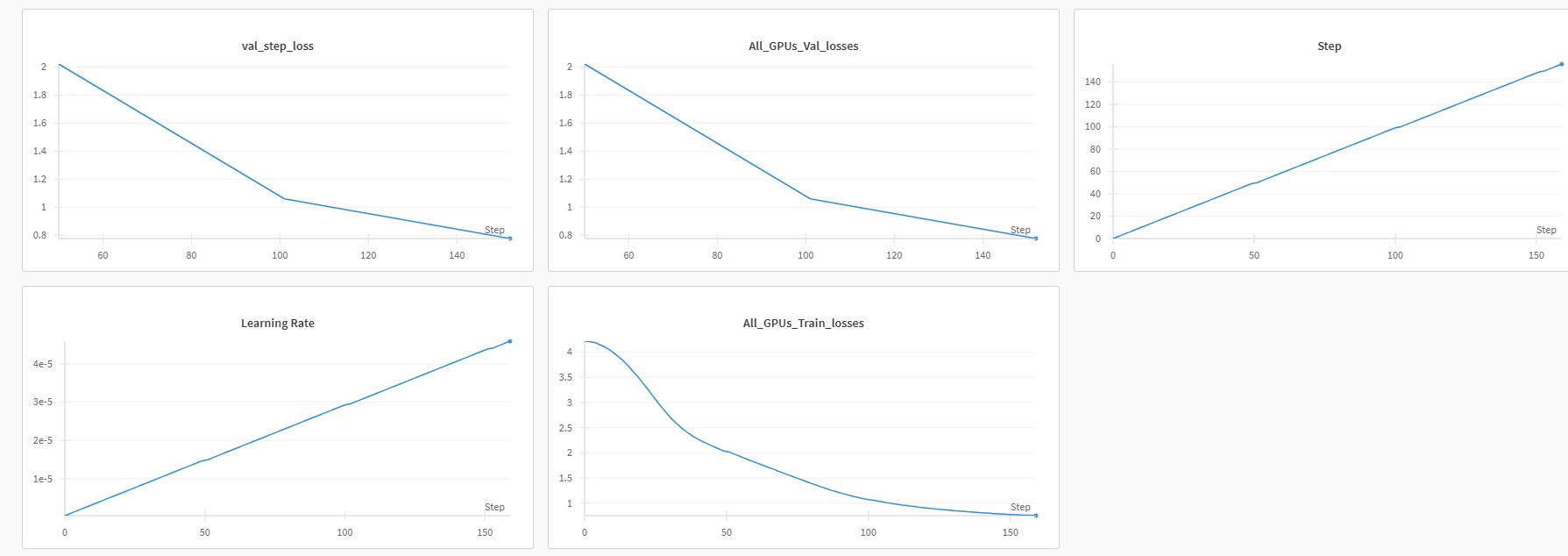
Epochs/Steps
Steps (train) = 150
Val iterations = every 50 steps
Loss Curves
{kind=link}
Source Code
📁 GitHub Repository: TTS
View the complete implementation, training scripts, and documentation on GitHub.