
Moonshine
Moonshine
Overview
From scratch implementation of Moonshine
Technical Details
- Framework: PyTorch
- Dataset: Gigaspeech
- Category: Audio/Speech
Implementation Details
Trained a small transformer-based ASR model coded and trained from scratch in Pytorch.
Moonshine: Speech Recognition for Live Transcription and Voice Commands
Hyperparameters
| Parameter | Value | Description |
|————————–|————|—————————————————————————–|
| epochs | 10 | Total training epochs. |
| batch_size | 128 | Samples per batch. |
| block_size | 40 | Context window length for attention. |
| embeddings_dims | 288 | Embedding dimension (must be divisible by no_of_heads). |
| no_of_heads | 6 | Attention heads in multi-head attention. |
| no_of_decoder_layers | 6 | Transformer decoder layers. |
| dropout | 0.1 | Dropout rate for regularization. |
| max_lr | 6e-4 | Peak learning rate (use with learning rate scheduler). |
| weight_decay_optim | 0.1 | Weight decay for AdamW (consider reducing to 0.01 if unstable). |
| sr | 16000 | Audio sampling rate (fix conflict with SAMPLING_RATE=480000 if needed). |
Dataset
Frameworks:
Pytorch
Epochs/Steps
Steps (train) = 1500
Val iterations = every 50 steps
Loss Curves
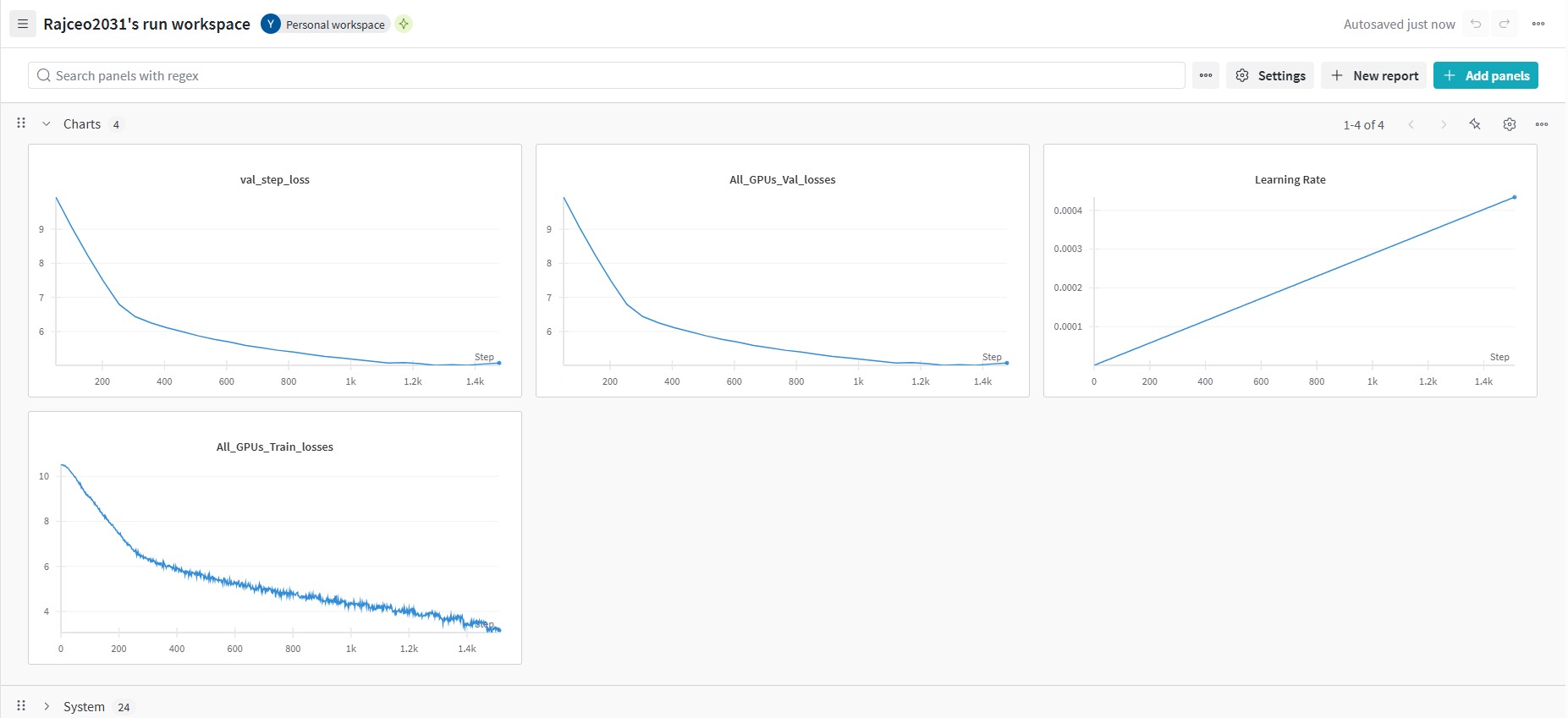{kind=link}
Looks like 25 hours isnt enough thus started to overfit!
Source Code
📁 GitHub Repository: Moonshine
View the complete implementation, training scripts, and documentation on GitHub.