
Llama4
Llama4
Overview
From scratch implementation of Llama 4 Scout
Technical Details
- Framework: PyTorch
- Dataset: Custom
- Category: Language Models
Implementation Details
- So, I trained a MoE based Llama 1.2B (32x12M) architecture I coded from ground up.
- Trained on TiyStories dataset form HuggingFace consisting of 4.2B tokens for 1 FULL epoch.
Pretraining
Dataset
- I used the TinyStories dataset from HuggingFace.
1) Train dataset - 2 M records approx 2) Val dataset - 26K records approx
Model Configuration (ModelArgs)
This dataclass defines hyperparameters and configuration settings for a neural network model, optimized for modern deep learning tasks.
Hyperparameters Overview
Architecture
| Parameter | Value | Description |
|---|---|---|
block_size |
1024 | Context window length for sequential data |
embeddings_dims |
768 | Dimension size for embeddings |
no_of_heads |
8 | Number of attention heads in multi-head attention |
no_of_decoder_layers |
8 | Number of transformer decoder layers |
vocab_size |
32000 | Vocabulary size from tokenizer |
base_freq |
10000 | Base frequency for positional encodings |
Training
| Parameter | Value | Description |
|---|---|---|
epochs |
1 | Total training epochs |
batch_size |
16 | Samples per batch |
max_lr |
6e-4 | Maximum learning rate |
clip |
1.0 | Gradient clipping threshold |
Regularization
| Parameter | Value | Description |
|---|---|---|
attn_dropout |
0.1 | Dropout probability for attention layers |
dropout |
0.1 | General dropout probability |
Optimization
| Parameter | Value | Description |
|---|---|---|
weight_decay_optim |
0.1 | L2 regularization strength |
beta_1 |
0.9 | AdamW first momentum factor |
beta_2 |
0.95 | AdamW second momentum factor |
eps |
1e-8 | Epsilon for numerical stability |
Mixture-of-Experts (MoE)
| Parameter | Value | Description |
|---|---|---|
experts |
31 | Total number of experts in MoE layer |
top_experts |
1 | Number of active experts per token |
noisy_topk |
False | Enable noisy top-k expert selection |
use_shared_expert |
True | Enable/disable shared expert |
useauxFreeLoadBalancingLoss |
True | Use auxiliary-free load balancing loss |
aux_free_bias_update_rate |
0.001 | Update rate for auxiliary-free bias |
Hardware & Optimization
| Parameter | Value | Description |
|---|---|---|
device |
‘cuda:4’ | Training accelerator (GPU/CPU) |
use_checkpointing |
False | Enable gradient checkpointing |
use_liger |
True | Use Liger kernels for optimized operations |
ignore_pad_token_in_loss |
True | Whether to ignore padding tokens in loss calculation |
-
Used P100 on Kaggle
Frameworks:
Pytorch
Epochs/Steps
-
Iterations (train) = 20k
-
Val iterations = every 400 steps
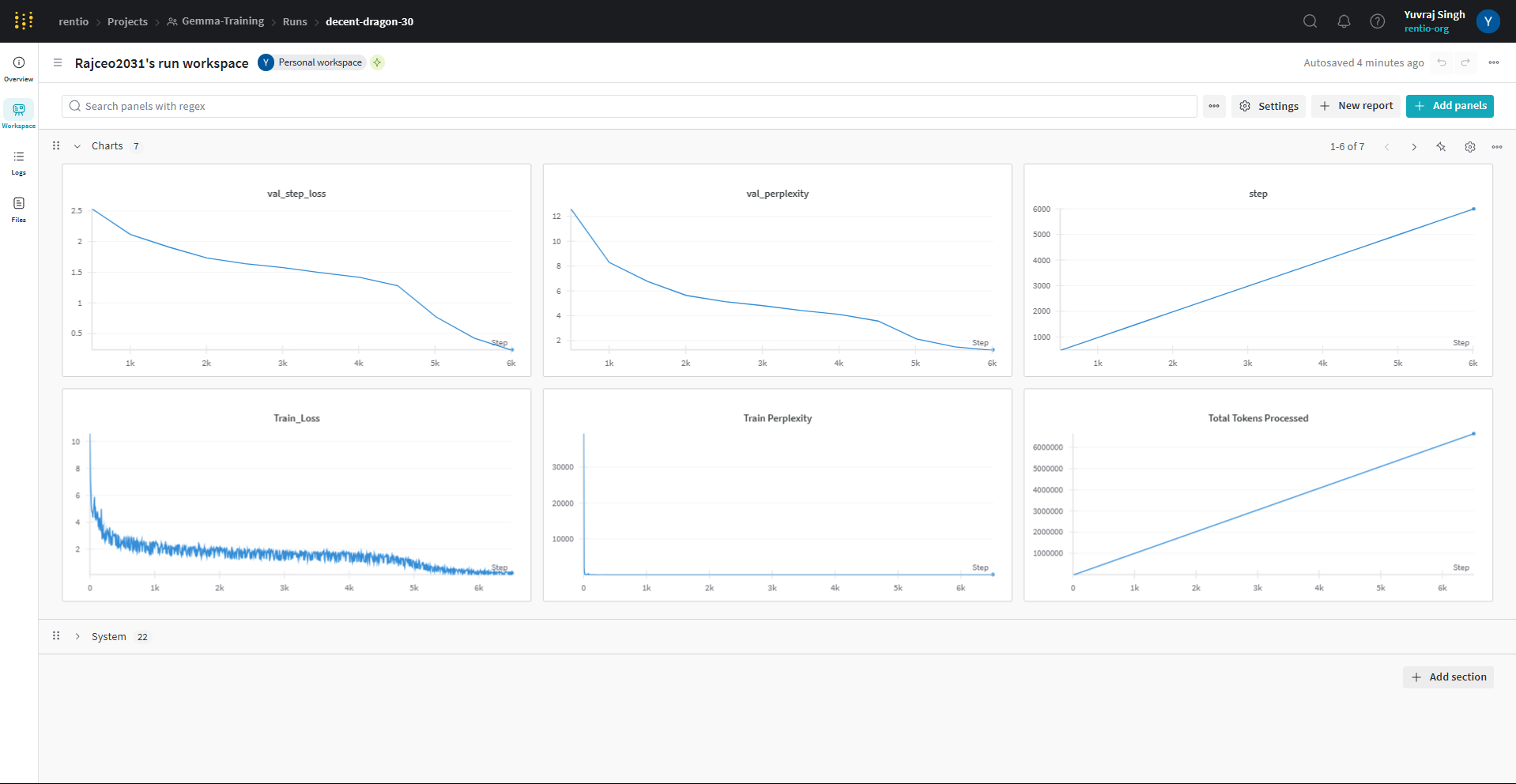
Losses
-
Train loss - 2.08
- Val loss - 1.7
Screenshots of the loss curves
- Loss Curves (Train and Val)
{kind=link}
Output
/data/generations.txt
Source Code
📁 GitHub Repository: Llama4
View the complete implementation, training scripts, and documentation on GitHub.