
Gemma3
Gemma3
Overview
From scratch implementation of Gemma3
Technical Details
- Framework: PyTorch
- Dataset: Custom
- Category: Language Models
Implementation Details
Trained a small Gemma 3 model (90M) coded and trained from scratch in Pytorch (text only)
ModelArgs Hyperparameters
| Parameter | Value | Description | |
|---|---|---|---|
batch_size |
64 | Number of samples processed before model update | |
max_lr |
2.5e-4 | Maximum learning rate | |
dropout |
0.1 | Dropout rate for regularization | |
block_size |
256 | Sequence length (number of tokens) | |
vocab_size |
32000 + 768 | vocabulary size | |
embeddings_dims |
512 | Token embedding dimensionality | |
attn_dropout |
0.1 | Dropout rate for attention layers | |
no_of_heads |
8 | Number of attention heads in multi-head attention | |
no_of_decoder_layers |
6 | Number of decoder layers | |
weight_decay_optim |
0.1 | Optimizer weight decay | |
beta_1 |
0.9 | Adam optimizer beta1 parameter | |
beta_2 |
0.95 | Adam optimizer beta2 parameter | |
no_kv_heads |
2 | Number of key/value heads | |
scaling_factor |
0.5 | Scaling factor for certain operations | |
local_block_size |
128 | Local attention block size | |
base_freq |
10000 | Base frequency |
Dataset
Frameworks:
Pytorch
Epochs/Steps
Steps (train) = 25000
Val iterations = every 500 steps
Loss Curves
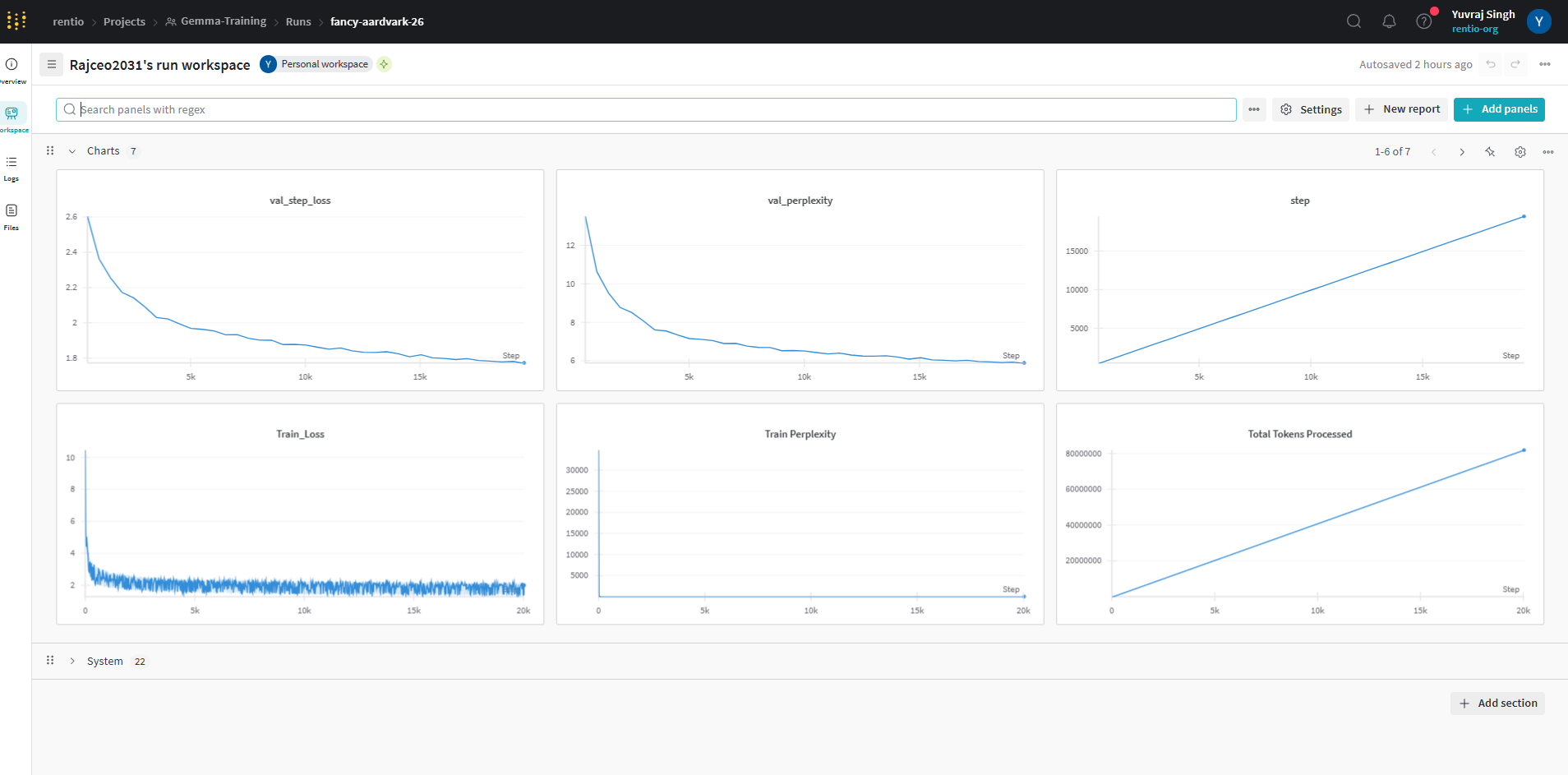{kind=link}
Train loss: 2.08 (last step)
Val loss: 1.77
Source Code
📁 GitHub Repository: Gemma3
View the complete implementation, training scripts, and documentation on GitHub.